FAQ
Some frequently asked questions
- Why did you invent Dasher?
- Who is Dasher aimed at?
- What gave you the idea for the inverse-arithmetic-coding interface?
- How does the text entry method work?
- How does arithmetic coding work?
- How does the model adapt to the writer’s language?
- How tiring is the method for the writer’s eyes?
- How fast is the method compared to other text-entry methods?
- How long does it take to learn to write English with Dasher?
- Can you describe a person writing a couple sentences using your method compared with existing methods?
- What were the technical challenges you had to address in order to make Dasher work?
- Was there anything surprising about the results?
- How much computing power does Dasher require?
- You say Dasher produced less spelling errors than standard methods. But were those errors evaluated in terms of seriousness?
- Twenty-five words per minute is not as fast as talking. Why would anyone use Dasher when they could use speech recognition instead?
- How does your work fit into the body of work on text compression, on text entry, and on human-computer interaction in general, and what is different about it?
- How could this research eventually be applied practically?
- Where is this type of input going in the long-term?
- You said that Dasher can work in most languages. How do you think it might be used in Japanese?
- How many people have used Dasher?
- What are the next steps in your research? What are you ultimately aiming for?
- When could the research be ready to be applied practically?
- When will a consumer version of Dasher be ready?
- Why make Dasher Open Source?
- Who funded the research?
- What is your job title?
- Is there anything else you’d like to say?
I (David MacKay) was convinced that standard text-entry systems (such as ten-finger keyboards) are very inefficient - they don’t make use of the predictability of natural language, and they waste our capabilities of making high-precision gestures.
I believed that by starting from a principled foundation - namely information theory - we could make completely new writing systems that could have hardware much smaller than keyboards, and yet work nearly as fast, and that could be integrated with pointing systems such as eyetrackers.
There are several different groups of people who will find Dasher useful. What they all have in common is that they want an alternative to the regular ten-finger keyboard.
-
The largest group of people who can’t use full-size keyboards are palmtop computer users. Many people who’ve downloaded the version of Dasher for pocket PC say they find it easy to learn and enjoyable to use.
-
The group for whom we think Dasher offers the biggest benefits are people with special needs. Many people who can’t use a ten-finger keyboard, but who can use a regular mouse, joystick, roller ball, touch screen, or head-mouse (and who can see their computer screen), will find Dasher useful. Within 10 minutes, such users can write with Dasher at speeds in the range of 5 to 15 words per minute. After 60 minutes of practice, writing speeds range from 15 to 25 words per minute. With further practice, 39 words per minute can be reached.
For severely disabled people who cannot use any of the above pointing systems, but who do have the use of their eyes, Dasher offers big potential benefits if it is used with an eyetracker. With practice, writing speeds of 20-25 words per minute can be achieved.
-
Another group for whom regular “qwerty” keyboards are inconvenient are Japanese computer users. The roman alphabet is unfamiliar to many of them, so writing in Japanese via a roman keyboard is cumbersome. Dasher can be used in almost any language, and we have made a Japanese prototype that allows one to write in the phonetic Hiragana alphabet.
What gave you the idea for the inverse-arithmetic-coding interface?
I (David MacKay) was on a bus to Denver airport with Mike Lewicki on December 7th 1997. I was entering something in my PDA (a Psion 3a, which has a small qwerty keyboard), and Mike commented `gee, that thing is so big!' And this set us thinking, `how could we make a smaller PDA, given that the limiting thing is the keyboard?' We brainstormed about how to make a device with a tiny display mounted on a pair of glasses and with an input device no bigger than 2cm by 2cm, which could be attached to the lapel of your jacket. You’d drive it with your finger.
We were convinced that we could make something much more efficient than a regular keyboard; the keyboard is inefficient for two reasons. First, in ordinary writing, every character must be entered by a distinct finger-gesture; but ordinary text is highly redundant - highly predictable. The information content of ordinary text is only one or two bits per character. So one of our aims was to incorporate a language model into the heart of the text entry device to exploit this predictability and reduce the load on the user. Second, human fingers, although they are called `digits', are analogue devices, capable of fine continuous gestures. The clunky keyboard throws away our ability to make high-precision gestures by forcing us to make binary gestures as we tap the keys. We estimated that a single finger can in principle generate information at a rate of about 24 bits per second.
If we could find a new way to couple a single finger (producing information at 24 bits per second) to a really good language model (which knows how to compress text into one bit per character) then perhaps we could write at 24 characters per second!
At this point I had the idea of making an inverse-arithmetic-coder.
The user could steer the interface with two-dimensional pointing, on a 2-d trackpad for example; and in fact since the user would be looking where they were going, we didn’t even need the trackpad: we could use an eyetracker to obtain the same steering information.
Thus was born the idea of `Dasher'. (This name was Mike’s suggestion.) Mike reckoned the best way to write a prototype would be in the Tcl language, and by the time we got to Denver airport, Mike had taught me enough Tcl that I had knocked together a primitive zooming interface.
Within another week I had finished the first prototype.
I had an additional motivation for making this prototype of Dasher: since Dasher is an inverse arithmetic coder, it served as a handy teaching aid for teaching arithmetic coding in my Senior course on Information Theory, Pattern Recognition, and Neural Networks. I’ve used it to teach arithmetic coding every year since January 1998.
It’s hard to explain in words. Even with pictures, it’s hard to explain! (An online explanation with pictures can be found here) It’s easiest to explain by a live demonstration. Anyway, here goes.
Imagine a library containing all possible books, ordered alphabetically on a single shelf. (Yes, I mean all possible books. This library is sometimes called the Library of Babel.) Books in which the first letter is “a” are at the left hand side. Books in which the first letter is “z” are at the right. The first book in the “a” section reads “aaaaaaaaaaaa…"; somewhere to its right are books that start “all good things must come to an end…"; a tiny bit further to the right are books that start “all good things must come to an enema…”.
When someone writes a piece of text, their choice of the text string can be viewed as a choice of a book from this library of all books - namely, the book that contains exactly the chosen text. How do they choose that book? Let’s imagine they want to write “all good things…”
First, they walk into the “a” section of the library. There, they are confronted by books starting “aa”, “ab”, “ac,…. “az” Looking more closely at the “al” section, they can find books starting “ala”, “alb”,… “alz”
By looking ever more closely at the shelf, the writer can find the book containing the text he wishes to write. Thus writing can be described as zooming in on an alphabetical library, steering as you go.
This is exactly how Dasher works, except for one crucial point: we alter the SIZE of the shelf space devoted to each book in proportion to the probability of the corresponding text. For example, not very many books start with an “x”, so we devote less space to “x…” books, and more to the more plausible books, thus making it easier to find books that contain probable text.
The result is that instead of having the laborious feeling of selecting one letter at a time - as on a typewritter - the user has the feeling that whole syllables, whole words, even whole phrases, are simply leaping towards him.
The user steers by pointing where he wants to go. The display zooms in towards wherever the user points. And because the user is typically looking where he wants to go, it’s not essential for the user to point; we can simply track his eyes and use gaze direction as the pointer.
Arithmetic coding is a beautiful text compression method. It normally takes me a one-hour lecture to explain it.
Imagine a ruler (a straightedge) of length one foot. Put a mark half-way down it. Label the left half “0” and the right half “1”. Now halve the left half, and label the two quarters “00” and “01”. Similarly, halve the right half, and label the two quarter “10” and “11”. Now we have defined six intervals: “0” and “1”; and “00”, “01”, “10”, and “11”. We can keep subdividing the last four, and get eight intervals such as “000” and “101”. Thus, any little chunk of ruler can be associated with a binary string.
Now, text compression depends on there being redundancy in the text, and any redundancy can be described by a probabilistic model, which says what the probability of the first character in the document is, and what the probability of the second is, given the first, and so forth. Arithmetic coding assumes that you have got such a model from somewhere.
Let’s take the predictions of the probabilistic model: say the predictions for the probabilities of the first character (a,b,c,….z) are P(a)=0.05; P(b)=0.02; P(c)=0.03; … P(e)=0.10; … P(t)=0.20; ….
We can use these probabilities to slice up the ruler. The left-hand 5% of the ruler is called “a”; the next 2% is called “b”; and so forth.
Then we can subdivide the ruler’s “a” portion into “aa”, “ab”, “ac”,… in proportion to the probabilities assigned by the probabilistic model when we ask `assuming the first character is an “a”, what’s the probability of the second character?'
In this way, every possible string of characters is associated with a little fragment of ruler. Then the arithmetic coding method simply encodes the given string by finding the shortest binary string associated with the same chunk of ruler.
We use a language model called PPM (prediction by partial match). This language model makes its predictions by counting how often each letter occurred in similar contexts in the training text. The model can easily be adapted by adding whatever the user writes to the training-text database. It works with almost any language.
We can’t imagine a more user-friendly method for writing with one’s eyes. It’s similar to driving a car. When you drive a car, your eyes spend much of the time looking at the point that you want to drive towards. So in principle, you could imagine getting rid of the steering wheel and simply having the car steer towards wherever your eyes are looking. This hands-free driving system would not be any harder on the driver’s eyes than regular driving.
Similarly, writing with Dasher feels almost effortless. You simply look on the screen for the first syllable you want to write; it zooms past you, and the next possible syllables appear; most of the time, the next one you want is easy to spot, and you spot it, and it zooms by, and the next options appear. No conscious control of the eyes is needed.
Using simple and cheap eyetrackers, for any application, can be tiring because the eyetrackers can be confused by a blinking eye or poor calibration. However, this is a problem of those eyetrackers, not Dasher.
Our paper, Fast Hands-free Writing by Gaze Direction, published in Nature on August 22 2002, describes a comparison of Dasher-driven-by-an-eyetracker with an on-screen keyboard, with word-completion, driven by an eyetracker. Dasher users could write at up to 25 words per minute after an hour of practice. On-screen keyboard users could write at only 15 words per minute after the same time. Moreover, the error rate when using the on-screen keyboard was about five times that of Dasher. It’s hard to make spelling mistakes with Dasher, because the language model makes it easy to select correct spellings.
Speed and error-rate are not the only important factors. Users who tried both systems reported that they found the on-screen keyboard more stressful for two reasons. First, one feels uncertain whether an error has been made in the current word (the word-completion feature only works if no errors have been made); one can spot an error only by looking away from the keyboard. Second, at every character, one has to decide whether to use the word completion or to continue typing; looking in the word-completion area is a gamble since one cannot be sure that the required word will be there; finding the right completion requires a switch to a new mental activity.
In contrast, Dasher users can see simultaneously the last few characters they have written and the most probable options for the next few. And Dasher is a mode-free device: it makes no distinction between word-completion and ordinary writing.
We have also compared Dasher, driven by a mouse, with other pointer-based text-entry systems. All users get faster with practice, and expert writing speeds, using a mouse, have reached 39 words per minute. This is not as fast as full, ten-finger typing speeds on a full-size keyboard, but of course we require neither a bulky keyboard nor the two hands required to use it. We are using only one finger!
We can tell you results for the mouse-driven version of Dasher, and for the eye-tracking version.
- Using a mouse to steer: Within 10 minutes, novice users of Dasher can write in English at speeds in the range of 5 to 15 words per minute. After 60 minutes of practice, writing speeds range from 15 to 25 words per minute. Our most experienced Dasher user, David Ward, can write at 39 words per minute. (Some Experimental results online))
- With the eye-tracker, novices can write English at 7 words per minute after 10 minutes, and at 12-15 words per minute after 60 minutes practice. Users with more experience of Dasher can write at 20-25 words per minute.
When you use a standard on-screen keyboard, you have to stare at the first character you want for a specified dwell time (half a second, say), then stare at the next character, and so forth. This feels terribly slow and tiring. Eyes did not evolve to press buttons! If you reduce the dwell time, it still feels slow and tiring, though not quite so slow as before; but the reduced dwell time leads to errors, because you accidentally `dwell' on incorrect keys. To speed up your writing, you have the option of looking at a small number of extra keys at the top of the keyboard in which word-completions are offered. Because you can only read what you are looking at, the only way to find out what word-completions are on offer is to make the decision to go and look in this word-completion area. You then have to scan around, trying not to dwell for too long on any displayed word, and either select the right word, if you find it, by staring at it, or give up and revert to typing. If you revert to typing, you had better remember what letter you just got to! You can remind yourself what letter you got to only by looking in another area of the screen. It’s hard to know if you have made errors when typing, so the value of word-completion is reduced. It’s likely you’ll spell a number of words wrong in your sentence.
When you write the same sentence using Dasher, the initial display shows all characters a-z vertically. You look at the first character of the sentence, and the display zooms in on that character, revealing continuations of the sentence inside the first character; you look at the continuation you want, and the display zooms in on that. The whole process is continuous. There are no discrete acts of selection. Just a little to the left of where one is looking, one can see the characters one has already chosen queuing up to the left; to the right, one can see possible continuations, arranged alphabetically. It feels like you’re being offered word-completions, and at the same time, what you’re doing is writing by selecting letters from the alphabet. Errors are rare, once you have used Dasher for an hour or so. If you do make an error, you typically notice right away, because the model doesn’t predict the characters you want to write next. You can correct errors by backing up – looking to the left of the screen instead of the right – then going forwards again.
David Ward did the hard work of turning the prototype into a fast, useable, effective, and beautiful piece of software, and testing it. Important issues were
- the trade-off between using the CPU to refresh the moving image on the computer screen, and using the CPU to compute additional predictions of the language model;
- the details of nonlinearities in the rendering of the screen-image and nonlinearities in Dasher’s dynamics. The original linear version worked OK, but David managed to enhance the maximum writing speed substantially by introducing clever nonlinearities.
The limiting factor in the eyetracking version of Dasher is the resolution of the eye-tracker.
We were delighted with how much faster we can write with Dasher and an eyetracker than the writing speeds many disabled computer users report. We know of one user who can write at only 6-9 words per minute. We hope that he’ll give Dasher a try, because it can probably triple his writing speed.
** You say Dasher produced less spelling errors than standard methods. But were those errors evaluated in terms of seriousness? I mean, a mispelling is easily detected by a reader. A different word acidentally chosen can change the whole meaning. Have you evaluated this qualitative aspect?**
That’s a very good question. We haven’t formally investigated this issue, but I can give you some raw data, and an informal impression. I think most of the misspellings were minor, and many of them were caused by uncertainty about how to spell Jane Austen’s prose!
Here is what I wrote in my 9th eyetracking session, in which I made 5 errors, according to the graph. [Punctuation and upper case characters were not required, except that ends of sentences were meant to be marked with ‘__’.]
thewoodhouses_were_first_in_consequence_there__all_looked_up_to_them__she_had_ma ny_acquaintance_in_the_place_for_her_father_was_universally_civil_but_not_one_am ong_them_who_could_be_accepted_in_lieu_of_miss_taylor_for_even_half_a_day__it_wa s_a_melancholy_change__and_emma_could_not_but_sigh_over_it_and_wish_for_impossib le_things_till_her_father_awoke_and_made_it_ncessary_to_be_cheerful__his_spirits _required_support__he_was_a_nervous_man_easily_depressed__fond_of_every_body_tha t_he_was_used_to_and_hating_to_part_with_them__hating_change_of_every_kind__
And the correct text (with error locations highlighted by *) was
TheWoodhouses were first in consequence there. All looked up to them. She had many acquaintance in the place, for her father was universally civil, but not one among them who could be accepted in lieu of Miss Taylor for even half a day. It was a melancholy change; and Emma could not but sigh over it, and wish for impossible things, till her father awoke, and made it necessary to be cheerful. His spirits required support. He was a nervous man, easily depressed; fond of every body that he was used to, and hating to part with them; hating change of every kind.
This example shows two errors that are not severe. I can’t spot the other three! Let’s look at another example, trial 12. (4 errors according to the graph.)
the_real_evils_indeed_of_emmas_situation_were_the_power_of_having_rat her_too_much_her_own_way_and_a_disposition_to_think_a_little_too_well _of_herself__these_were_the_disadvantages_which_threatened_alloy_to_h er_many_enjoyments__the_danger_however_was_at_present_so_unperceived_ that_they_did_not_by_any_means_rank_as_misfortunes__sorrow_came_a_gen tle_sorrow_but_not_at_all_in_the_shape_of_any_disagreeable_consciousn ess__miss_taylor_married__it_was_miss_taylors_loss_which_first_brough t_grief__it_was_on_the_wedding_day_of_this_beloved_friend_that_emma_f irst_sat_in_mour
The real evils, indeed, of Emma’s situation were the power of having rather too much her own way, and a disposition to think a little too well of herself; these were the disadvantages which threatened alloy to her many enjoyments. The danger, however, was at present so unperceived, that they did not by any means rank as misfortunes *with* *her*. Sorrow came – a gentle sorrow – but not at all in the shape of any disagreeable consciousness.– Miss Taylor married. It was Miss Taylor’s loss which first brought grief. It was on the wedding-day of this beloved friend that Emma first sat in mournful thought of any continuance.
Again, in this example, I can only find two errors (the two omitted words). I hope these examples give an impression of how reliable Dasher is, once one has some practice. It is hard to make mistakes, because one can always see what one has just written. If one wrote the wrong word, one would notice, I think.
Dasher can be used with any ordinary mouse, with a touch-screen, or with an eyetracker. The vast majority of Dasher users use it with a regular mouse or with a touch screen. With a mouse or touch screen, speeds up to 35 words per minute can be attained with practice. 25 words per minute is quite typical after an hour of practice.
This is indeed slower than talking speed, so if someone can use speech recognition technology then maybe they have no need for Dasher.
However, many people like Dasher because
- it gives them a silent way to write - no key-tapping noises even!
- some people can’t get speech recognition technology to work.
- You can use Dasher on any computer, whereas you can only use speech recognition on a computer that has been trained on your voice.
- Speech recognition can’t be used in a noisy environment.
- Speech recognition requires a head-mounted microphone, and requires the user to learn a lot of new skills – learning to use a speech recognition system probably takes several days, whereas you can get going with Dasher within 5 minutes, and one hour is plenty of practice to achieve 25 words per minute.
- Dasher can be used on a tiny pocket PC, too small to have a satisfactory speech recognition system.
- An experienced Dasher user makes almost no writing mistakes at all. Even the most well-trained speech-recognition user with the clearest speech finds that the system makes errors for about 5% of the words they write.
Dasher can easily be run on any standard PC (running Windows or GNU/Linux). It also runs fine on the more-powerful palmtop computers such as the pocket PC. The eyetracking version of Dasher has only been used with standard PCs thus far, as we haven’t come across a palmtop with an eyetracker :-)
Dasher is distinctive because it uses human body’s natural continuous gestures, rather than forcing the human to emit binary gestures (as in typing) or discrete symbols (as in handwriting or `graffiti'). Eyes are good at navigation and search, and those are the skills that the eyetracking version of Dasher uses.
Dasher is also distinctive because it integrates a language model into a writing system in a mode-free manner. Many writing systems use a language model to offer word-completions, but accepting a word-completion involves a change in mode. We think Dasher is especially easy to use because it does not require these mode-changing decisions.
Dasher is also distinctive because it requires little learning. If the user is familiar with the alphabetical order used on the screen, then the only skill to learn is a simple steering skill analogous to the skill of steering a car. This skill is transferrable. If an experienced user wishes to write in Hiragana (the Japanese phonetic alphabet) instead of English, he can do so instantly. All we need to do is train the language model on Hiragana, and load up the right fonts. A user who can write at 25 words per minute in English will be able to write at 25 words per minute in Japanese too (assuming he knows both languages!). Similarly, in English, we can add extra characters to the Dasher alphabet (for example upper case as well as lower case), and the user is able to write just as fast as before, even though the number of characters available has doubled. Extra characters for European languages can easily be included. There is no need to make major modifications in order to add ten accented characters to the alphabet, as there would be in other approaches using keyboards or graffiti.
Dasher’s use of training text is distinctive. Many systems that employ language models presume that the language consists of words, and the predictions of the model are embodied in word-completions. Our language model makes no such presumption, but it often behaves like a word-completion system. Moreover, Dasher often does a good job of predicting what word comes next. But Dasher does this without having any concept of “words”. If a user chose to write documents in which the space characters are omitted, or replaced by “X”, the language model will work just fine; if the user repeatedly uses entire phrases, then Dasher will behave like a phrase-completion device.
Dasher can be instantly personalized: simply train the language model on some example documents similar to the one you intend to write.
Dasher works instantly in any language: simply train the language model with example documents in the desired language.
*** How could this research eventually be applied practically? What other types of uses might the efficient method for text compression eventually lead to?**
We think that Dasher could be used in at least three communities, and that the software that David Ward has created is almost ready for use in at least one of them.
First, the disabled community: Dasher offers a way to enter text into computers for people who cannot use ten-finger qwerty keyboards. Some disabled computer users who have generously tested Dasher report that they find it far better than any other writing method they have tried. We expect that Dasher, controlled by a touch-pad, joystick, mouse, head-mouse, roller-ball, or eyetracker, will transform the writing speed of many disabled users.
Second, Dasher offers a new keyboardless text-entry method for computer users in extreme environments. Until now, head-mounted displays for tiny portable computers have hardly taken off at all; we think the reason for this is that an appropriate text-entry method has been lacking. Dasher driven by an eyetracker or a miniature trackpad offers a new solution to this problem. We have developed a version of Dasher that runs on a pocket PC. Maybe some palmtop users will prefer to use Dasher for text entry.
Third, we believe that Dasher might be especially useful to Japanese computer-users. Many Japanese users are only slightly familiar with the qwerty alphabet, yet most computers in Japan have qwerty keyboards; so writing in Japanese on a keyboard is quite slow. Dasher offers a way to write in Japanese that bypasses the qwerty keyboard. We are at present testing a Hiragana prototype.
Other more speculative uses for Dasher include:
Hybrid voice-dasher system
Speak into an imperfect speech-recognizer, and watch as its inferences are displayed as predictions; wherever it is not sure what you said, use Dasher to steer into the correct sentence. Much easier than having to correct errors by saying further speech-commands!
Hybrid automatic translation-Dasher system
Assume we have a poor translation system that translates badly from French to English. An expert has to zip through the translation and clean up errors. This cleaning-up could be done within Dasher, using the output of the translator to define a language model.
I think the long term is already here. Right now, one of our disabled friends is using Dasher to write documents. We are ready now for product development, shrink-wrapping, and promotion.
As a first step towards a full Japanese version of Dasher handling both Kana and Kanji, David Ward has written a Hiragana version, “Daishoya”, available in Windows version 1.6.3 of Dasher and GNU/Linux versions 1.6.3-1.6.8.
A demonstration of “Daishoya” being used to write 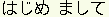 (hajime mashite) can be reached from www.inference.phy.cam.ac.uk/dasher/Languages.html.
(hajime mashite) can be reached from www.inference.phy.cam.ac.uk/dasher/Languages.html.
The conversion of Dasher to Daishoya is simple: we replace the English alphabet a..z by the Hiragana alphabet, 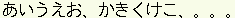 (a,i,u,e,o,ka,ki,ku,ke,ko…). We replace the English training text by a Hiragana document. [Unfortunately, we have not been able to find a large pure-Hiragana document, so our language model is not as well-trained as we would like.]
(a,i,u,e,o,ka,ki,ku,ke,ko…). We replace the English training text by a Hiragana document. [Unfortunately, we have not been able to find a large pure-Hiragana document, so our language model is not as well-trained as we would like.]
Daishoya then allows you to write Hiragana text without a keyboard.
In the long term, we can imagine two ways of using Daishoya to write Kanji:
- We could add a special character (like the enter key in Japanese Word) meaning “convert to Kanji”, and use a language model to predict which Kanji are the most probable in the given context and given the Hiragana sequence just written. All the probable Kanji would be displayed in boxes of size proportional to their probability, in accordance with the Dasher method. The user would zoom into the desired Kanji.
- We could make a new version of Daishoya in which the symbols in the alphabet are not Kana, but Kanji elements - single strokes, for example. The user would build up each Kanji character by adding one element at a time.
It’s hard to keep count. As of August 2002, we estimate that about 50,000 users have downloaded Dasher.
The first, and most important aim has already been achieved – we aimed to make a system that would allow people to write, without a keyboard, faster than they could write before. This dream has been realised.
As of October 2002, the Dasher project is being supported by the Gatsby charitable foundation. We are continuing to research the following topics:
- How to improve the language model. It’s already pretty good, but we can imagine that an extra 20% improvement in speed by improving the language model’s compression by 20%.
- Automatic calibration of the eyetracker. At present poor calibration of the eyetracker limits the performance of Dasher with eyetracker. We believe we can automatically tune the eyetracker on the fly, using the information supplied by the user’s steering corrections.
- Enhancements to the navigation mechanism for the eyetracker. When errors need to be corrected (which is not often!), the present version feels clumsy. We are working on a modified version of the navigation mechanism that will allow several alternative ways to back up and correct errors.
- How well the Japanese version of Dasher works for Japanese users.
- Making a version appropriate for people who can only convey one dimension of pointing rather than two dimensions. (This one-dimensional mode is included as an option in Dasher version 3.0.1, available March 2003.)
- Including a control mode within Dasher so that a user who cannot press a button to stop and start Dasher can nevertheless stop and start Dasher from within Dasher, and so that they can carry out other control functions. This feature is going in Dasher version 3.2.
- When could the research be ready to be applied practically?
- When will a consumer version of Dasher be ready?
Product development and promotion is going to be handled as an Open Source project. The research version of Dasher, available now, is already useful to some disabled computer users, and we expect the open source community to deliver something close to a shrink-wrapped consumer version within 12 months. The source code will be released under the GNU public license late this Summer 2002. We hope that the version released by the end of September 2002 will be found useful by many consumers. Anyone wishing to support this project, please contact David MacKay.
Why make Dasher Open Source? Our work benefits immensely from the use of free software.
- We use the GNU/Linux operating system, provided free by Linus Torvalds and others.
- We use the gcc compiler and emacs editor, provided free by Richard Stallman.
- We use TeX and LaTeX, provided free by Donald Knuth and Leslie Lamport.
- We use tcl (Ousterhout), X windows (lots of people), bash (Brian Fox), and hundreds of other pieces of free software.
Having benefitted so much, it is clear to us that free software makes the world a happier place. We would have to have a good reason not to make our work free.
Our work at the University is mainly publicly funded. UK Taxpayers pay for the costs of the University. US taxpayers also paid for some of the software we use.
The most compelling reason for making software free is that the world is a more fun place to live in if everyone shares freely.
Making Dasher `free' software does not prevent businesses from selling it, as for example Red Hat sells GNU/Linux. If businesses do profit from Dasher, we would encourage them to make an appropriate donation to support our continuing work. The Dasher project was supported by the generosity of IBM Zurich research labs, who gave David MacKay a partnership award in recognition of his earlier freely-shared work on error-correcting codes.
We plan to distribute Dasher under the GNU public license (GPL) initially. [A later version of Dasher may be distributed under the LGPL if there is demand.] These licenses allow anyone to use the source code, and ensure that modified versions of the source code remain equally free to everyone.
Let me get this straight. Dasher seems like a really good idea and one that has the potential to be enormously popular (esp. in Japanese market) yet you are making it open source (for reasons you explain above). Doesn’t this mean that palm or sony or someone could make a killing from your idea?
Yes, it’s conceivable that a company will incorporate Dasher into their product and it will boost their sales. If so, good for them, and I hope they might give something back in return to the Free Software Community - we’d like support for a software development manager for Dasher in my group, for example.
There’s three reasons why I think software patents are a bad idea:
First, patents inhibit open discussion - it’s no fun doing science in a secretive environment, and communication is essential for progress; it’s unlikely I could recruit PhD students to work on ideas like Dasher if I forced them to keep my ideas secret; Dasher would never have got off the ground.
Second, software patents prevent the best software solutions from being used - a good example is the widely used “gif” format for images: compuserve and Unisys are apparently enforcing a patent on the compression algorithm that used to be used to make gif images nice and small. So everyone is essentially having to stop using what used to be a nice simple standard.
Third, I think it is pretty rare that the deserving inventor actually gets anything financially from a software patent. You can’t win. The people who benefit from patents are (a) patent lawyers; and (b) big corporations, which use patents as threatened weapons to force other companies to do deals. If I had a patent and a big corporation violated it, what could I do? They have more money to pour into legal battles than I do. And they would no doubt counter-sue, alleging that I was infringing a stack of their patents. Even in the physical world, patents seem pretty useless. Look at Mr Dyson with his bagless vacuum cleaners. Didn’t Hoover infringe his patent anyway, and didn’t it take him ten years of misery in court to get this recognised?
The blue-skies research of the Inference group is supported by the Gatsby Charitable Foundation and by a partnership award from IBM Zurich Research Laboratory.
The Dasher project has (thus far) been run on a shoe-string without applying for any other funding.
Support for further development of Dasher would be welcome!
David MacKay is _Reader* in Natural Philosophy_ in the Department of Physics at the University of Cambridge. He is also cofounder of the information technology company, Transversal.
[(*) A `Reader' would be a Professor on the U.S. academic job scale.]
David Ward, who did most of the hard work of converting the Dasher idea from dream to reality, was a PhD student in the Physics department. He now has his PhD and works for a software company in Cambridge.
We are happy to be referred to as David Ward and David MacKay, or Dr. David Ward and Dr. David MacKay.
Is there anything else you’d like to say?
Executable copies of the Dasher software can be downloaded for free from the Dasher project website, https://www.inference.phy.cam.ac.uk/dasher/. There are tips for new users on the website too. Don’t give up if it takes you a minute or two to get started - within ten minutes, you’ll be dashing along.
Please try it out!
Donations to support our research are always welcome.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.